基于python的一个https网站证书特征提取项目
0x1 思路
基本思路很简单:基于老师给的思路,首先收集到一百万个网站的csv数据集 具体如下图结构
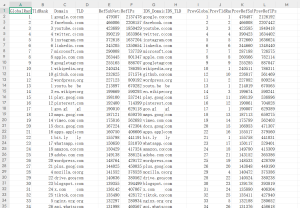
然后流程为 数据清洗(清洗出非https协议的和不可访问的网站 再将清洗后的数据写入到新的csv文件中) ——> 获取证书(将清洗后的网站csv文件读取 获取到其证书字典(或者元组)然后根据需要的部分提取出来 再次写入到新的csv文件中 便于数据的查询(其实对于这种大数据量还是做数据库最好)) ——> 数据可视化(由于数据获取的都为证书的特征,没有什么数理关系 于是直接做了一套 前后端查询web应用)
0x2 实现
首先说明对于这种百万级别的数据收集 多线程以及高并发问题是肯定不可避免的 而且使用python做这个项目也不是好的选择,最后我会给出go语言的版本
0x1 数据清洗:
读取文件 获取到Domain列 然后按行读取domain
首先需要规定协议为https 然后将domain和protoc ol结合获取到url 通过发送请求获取到回应状态码 根据状态码判断是否可访问
可访问:将域名写入到output文件按列写入 便于后面提取
不可访问:continue
代码实现:
import csv
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
def is_domain_accessible(domain, timeout=5):
try:
# 优先尝试HTTPS(更常见)
protocols = ["https://"]
for protocol in protocols:
url = f"{protocol}{domain}"
try:
response = requests.get(url, timeout=timeout)
if response.status_code == 200:
print(f"域名 {url} 可访问")
return True
except requests.exceptions.RequestException:
continue # 失败则尝试下一个协议
print(f"域名 {domain} 不可访问")
return False
except Exception as e:
print(f"域名 {domain} 访问失败: {e}")
return False
def main(input_csv, output_csv="select.csv", max_workers=20):
accessible_domains = []
try:
with open(input_csv, "r", encoding="utf-8") as file:
reader = csv.DictReader(file)
domains = [row.get("Domain", "").strip() for row in reader if row.get("Domain", "").strip()]
except FileNotFoundError:
print(f"文件 {input_csv} 未找到,请检查路径是否正确。")
return
# 多线程并发检查
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_domain = {executor.submit(is_domain_accessible, domain): domain for domain in domains}
for future in as_completed(future_to_domain):
domain = future_to_domain[future]
try:
if future.result():
accessible_domains.append(domain)
except Exception as e:
print(f"检查域名 {domain} 时发生错误: {e}")
# 写入结果到CSV
try:
with open(output_csv, "w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["Domain"])
writer.writerows([[domain] for domain in accessible_domains])
print(f"所有可访问的域名已保存到 {output_csv}")
except Exception as e:
print(f"写入文件失败: {e}")
if __name__ == "__main__":
main("majestic_million2.csv", "select.csv", max_workers=150) # 调整max_workers控制并发数
0x2 获取证书:
首先读取筛选后的csv文件 获取到域名
将域名作为参数传入到证书获取函数 开启线程池 将任务分配给workers
workers 分别执行获取证书函数
获取证书首先 创建ssl连接 然后使用socket连接 获取到ssocket 调用getpeercer方法 将返回的结果存储为cert
将证书字典的每个特征解析 获取到每个特征 将特征分别写入到headers中 然后保存为新的csv文件(对于获取到的证书的解析 首先需要开多个括号 因为其获取到时只使用get是大概率获取不到信息的 因为是元组 所以需要处理括号 同时需要处理时间信息 将其转换为正常信息)
代码:
import csv
import ssl
import socket
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime
def get_certs(input_csv='select.csv', output_file='certs.csv', max_workers=100):
domains = []
try:
with open(input_csv, 'r', encoding='utf-8') as f:
domains = [row[0].strip() for row in csv.reader(f) if row]
print(domains)
except FileNotFoundError:
print(f"文件 {input_csv} 未找到")
return
start_time = datetime.now()
print(f"开始处理 {len(domains)} 个域名,最大并发数:{max_workers}")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {}
for domain in domains[:50]:
hostname = extract_hostname(domain)
futures[executor.submit(get_ssl_certificate, hostname)] = domain
results = []
for idx, future in enumerate(as_completed(futures), 1):
domain = futures[future]
try:
cert = future.result()
results.append(cert)
# status = "✅ 成功" if cert else "❌ 无证书"
# print(f"[{idx}/{len(domains)}] {status} | {domain}")
except Exception as e:
results.append(None)
# print(f"[{idx}/{len(domains)}] ❌ 异常 | {domain} | {str(e)}")
save_certificates_to_file(results, output_file)
print(f"\n处理完成!耗时:{datetime.now() - start_time}")
print(f"证书信息已保存到 {output_file}")
def extract_hostname(url):
""" 从URL中提取主机名 """
if '://' in url:
return url.split('://')[1].split('/')[0]
return url.split('/')[0]
def get_ssl_certificate(hostname, port=443):
""" 证书获取函数 """
try:
# 创建SSL上下文
context = ssl.create_default_context()
context.minimum_version = ssl.TLSVersion.TLSv1 # 支持TLS 1.0+
with socket.create_connection((hostname, port), timeout=10) as sock:
with context.wrap_socket(sock, server_hostname=hostname) as ssock:
cert = ssock.getpeercert()
return cert
except Exception as e:
print(f" ⚠️ 错误详情:{str(e)}")
return None
def save_certificates_to_file(all_certs, output_file):
headers = ["Domain", "Subject", "Subject Org", "Subject Country",
"Issuer", "Issuer Org", "Issuer Country", "Valid From",
"Valid To", "Serial Number", "Alternative Names", "Status"]
with open(output_file, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(headers)
for cert_info in all_certs:
if not cert_info:
writer.writerow([""] * len(headers[:-1]) + ["无法获取证书"])
continue
# 解析主体和颁发者信息
subject = parse_component(cert_info.get('subject', []))
issuer = parse_component(cert_info.get('issuer', []))
# 处理日期格式
valid_from = parse_date(cert_info.get('notBefore'))
valid_to = parse_date(cert_info.get('notAfter'))
# 处理SAN字段
san = parse_san(cert_info.get('subjectAltName', []))
# 构建CSV行
row = [
subject.get('commonName', ''), # 域名
subject.get('commonName', ''), # 主体通用名
subject.get('organizationName', ''), # 主体组织
subject.get('countryName', ''), # 主体国家
issuer.get('commonName', ''), # 颁发者通用名
issuer.get('organizationName', ''), # 颁发者组织
issuer.get('countryName', ''), # 颁发者国家
valid_from,
valid_to,
cert_info.get('serialNumber', ''), # 序列号
san, # 备用名称
"有效" if cert_info else "无效" # 状态
]
writer.writerow(row)
def parse_component(component):
""" 解析证书主体/颁发者元组结构 """
data = {}
for item in component:
# 处理多层嵌套结构
if isinstance(item, tuple):
if len(item) == 2 and isinstance(item[0], str):
# 直接键值对
k, v = item
data[k] = v
else:
# 嵌套元组结构
for sub_item in item:
if isinstance(sub_item, tuple) and len(sub_item) == 2:
k, v = sub_item
data[k] = v
return data
def parse_san(san_list):
""" 将SAN元组列表转换为字符串 """
return ', '.join([f"{k}={v}" for k, v in san_list])
def parse_date(date_str):
""" 标准化日期格式(Feb 10 11:33:33 2025 GMT → 2025-02-10)"""
if not date_str:
return ''
try:
dt = datetime.strptime(date_str, "%b %d %H:%M:%S %Y %Z")
return dt.strftime("%Y-%m-%d")
except:
return date_str
if __name__ == "__main__":
# 安装依赖:pip install pyopenssl
get_certs(max_workers=200)
0x3 数据可视化:
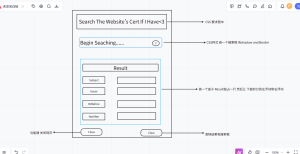
难度不高就是设计一个前端和一个查找后端 前端我用简单的html+css 后端使用flask框架做查找
前端思路如下:
 前后端代码:
html.index:
前后端代码:
html.index:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>SSL Certificate Lookup</title>
<style>
* {
padding: 0;
margin: 0;
box-sizing: border-box;
}
body {
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
line-height: 1.6;
padding: 20px;
background-color: #f0f8ff;
}
.title {
font-size: 48px;
text-align: center;
margin: 40px 0;
color: #2c3e50;
text-shadow: 2px 2px 4px rgba(0,0,0,0.1);
}
.search {
max-width: 800px;
margin: 0 auto 40px;
padding: 20px;
background: white;
border-radius: 15px;
box-shadow: 0 4px 10px rgba(0,0,0,0.1);
display: flex;
gap: 10px;
}
.search input[type=text] {
flex: 1;
padding: 15px;
font-size: 18px;
border: 2px solid #e0e0e0;
border-radius: 8px;
transition: border-color 0.3s;
}
.search input[type=button] {
padding: 15px 30px;
background: #4CAF50;
color: white;
border: none;
border-radius: 8px;
cursor: pointer;
font-size: 18px;
transition: background 0.3s;
}
.search input[type=button]:hover {
background: #45a049;
}
.result {
max-width: 1000px;
margin: 0 auto;
background: white;
border-radius: 15px;
box-shadow: 0 4px 10px rgba(0,0,0,0.1);
overflow: hidden;
}
.result-header {
background: #2c3e50;
color: white;
padding: 20px;
text-align: center;
font-size: 24px;
border-bottom: 3px solid #34495e;
}
.cert-info {
padding: 20px;
}
.info-row {
display: flex;
margin: 15px 0;
padding: 15px;
background: #f8f9fa;
border-radius: 8px;
box-shadow: inset 0 0 5px rgba(0,0,0,0.05);
}
.info-row:nth-child(even) {
background: #ffffff;
}
.info-label {
width: 200px;
font-weight: bold;
color: #2c3e50;
margin-right: 20px;
}
.info-value {
flex: 1;
word-break: break-all;
}
.error-message {
color: #e74c3c;
font-size: 18px;
padding: 20px;
text-align: center;
}
@media (max-width: 768px) {
.search {
flex-direction: column;
}
.info-row {
flex-direction: column;
}
.info-label {
width: 100%;
margin-bottom: 10px;
}
}
</style>
</head>
<body>
<div class="title">SSL Certificate Lookup</div>
<div class="search">
<input type="text" placeholder="Enter domain name..." id="domainInput">
<input type="button" value="Search" id="searchBtn">
</div>
<div class="result">
<div class="result-header">Certificate Information</div>
<div class="cert-info" id="certInfo">
<!-- 动态内容将显示在这里 -->
</div>
</div>
<script>
document.getElementById('searchBtn').addEventListener('click', function() {
const domain = document.getElementById('domainInput').value.trim();
const certInfo = document.getElementById('certInfo');
if (!domain) {
alert('请输入有效的域名');
return;
}
// 清空之前的结果
certInfo.innerHTML = '';
// 创建加载提示
const loading = document.createElement('div');
loading.className = 'info-value';
loading.textContent = 'Loading...';
certInfo.appendChild(loading);
fetch('/search', {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
},
body: `domain=${encodeURIComponent(domain)}`
})
.then(response => response.json())
.then(data => {
certInfo.innerHTML = ''; // 清空加载提示
if (data.status === 'error') {
const errorDiv = document.createElement('div');
errorDiv.className = 'error-message';
errorDiv.textContent = data.message;
certInfo.appendChild(errorDiv);
return;
}
const fields = [
'Domain', 'Subject', 'Subject Org', 'Subject Country',
'Issuer', 'Issuer Org', 'Issuer Country', 'Valid From',
'Valid Until', 'Serial Number', 'Alternative Names'
];
fields.forEach(field => {
const row = document.createElement('div');
row.className = 'info-row';
const label = document.createElement('div');
label.className = 'info-label';
label.textContent = field;
const value = document.createElement('div');
value.className = 'info-value';
value.textContent = data.data[field] || '无';
row.appendChild(label);
row.appendChild(value);
certInfo.appendChild(row);
});
})
.catch(error => {
console.error('Error:', error);
certInfo.innerHTML = '<div class="error-message">请求发生错误,请稍后重试</div>';
});
});
</script>
</body>
</html>
-------------------------------------------------------------------------------------------------------------------------------------
app.py代码:
import flask
from flask import Flask, request, jsonify
import pandas as pd
app = Flask(__name__)
# 读取CSV文件
df = pd.read_csv('certs.csv')
@app.route('/')
def index():
return flask.render_template('index.html')
@app.route('/search', methods=['POST'])
def search():
domain = request.form.get('domain', '').strip().lower()
if not domain:
return jsonify({'error': '请输入有效的域名'}), 400
# 在CSV中查找匹配的域名
result = df[df['Domain'].str.lower() == domain].to_dict('records')
if not result:
return jsonify({
'status': 'error',
'message': '该域名无法查找'
}), 404
# 处理空值显示为"无"
cert_info = {}
for key, value in result[0].items():
cert_info[key] = value if pd.notnull(value) else '无'
return jsonify({
'status': 'success',
'data': cert_info
})
if __name__ == '__main__':
app.run(debug=True)
-------------------------------------------------------------------------------------------------------------------------------------
0x3 展示
0x1:
文件结构
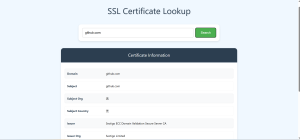
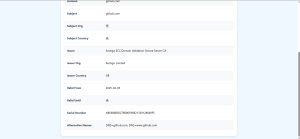
前端展示
0x4 扩展
由于python对于高并发处理的速度慢 做这种百万级别的数据处理是非常困难的 于是我使用go语言将这个项目做了速度优化
文件结构:使用go语言模块化处理(对go处于noob阶段 做的还不是很了解<3)

作者
xiangchao100321@outlook.com